REST API + Lambda + DynamoDB + Athena + QuickSight 연동하기
https://base.tistory.com/124
API 공공데이터 DB(AWS Aurora)에 삽입하기
API 데이터 활용을 위한 API 키 발급 DATA.GO.KR(공공데이터 포털)에 접속하여 원하는 데이터를 선택한 다음 "활용신청"을 클릭하여 API 서비스 키를 발급받는다 서비스 URL 확인 및 요청/응답 메세지
base.tistory.com
클라우드 아키텍처
아키텍처의 흐름은 다음과 같다
1. 마스크 착용 여부 및 체온 감지 데이터들을 REST API POST방식으로 값을 전달하면 API Gateway가 Lambda를 트리거하여 전달받은 값을 DynamoDB에 저장한다.
2. Athena를 활용하여 DynamoDB 데이터를 쿼리할 수 있도록 설정한다
3. Athena 데이터 커넥터를 사용하여 QuickSight에서 DynamoDB 데이터를 시각화한다

DynamodDB 테이블 생성
마스크 착용 여부 및 체온 감지 데이터들을 저장할 DynamodDB 테이블을 생성한다
(정렬 키 추가)


테이블이 생성되었으면 DB에 데이터를 저장하는 Lambda 함수를 생성해보자
Lambda 함수 생성
POST방식으로 전달받은 값을 DynamoDB에 저장하는 Lambda 함수를 생성한다
Lambda 함수가 DynamoDB에 항목을 작성해야하기 때문에 DynamoDB에 접근할 수 있는 역할을 부여한다 (없으면 역할 생성)

함수 코드 작성
TableName에는 미리 생성한 테이블명을 입력한다(테이블이 만들어져있지 않은 경우 에러가 출력됨)
REST API POST방식으로 전달받은 값들(event.temperature, event.mask ... event.check time )을 DB에 저장한다
var AWS = require('aws-sdk')
AWS.config.update({
region: 'ap-northeast-2',
endpoint: "https://dynamodb.ap-northeast-2.amazonaws.com" #DynamoDB EndPoint
})
const docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = function(event, context, callback) {
console.log(event);
let x = 1;
const y = x++;
var params = {
TableName: "OpenCV_result", #OpenCV_result라는 이름의 테이블을 미리 생성해놔야 한다
Item: {
"PK": "USER#" + y, #값을 전달받을 때마다 자동으로 1씩 증가
"SK": "DETECTION#" + y, #값을 전달받을 때마다 자동으로 1씩 증가
"user_id": event.user_id, #사용자(마스크, 체온 측정 기계를 사용하는 가게 사장님들)
"PN": event.PN, #마스크 착용 + 체온 등이 정상이면 Pass, 아니면 NonPass
"temperature": event.temperature, #체온
"mask": event.mask, #마스크 착용 여부
"check_day": event.check_day, #체크 일자
"check_time": event.check_time, #체크 시간
"location": event.location #체크 장소
}
};
docClient.put(params, function(err, data) {
if(err){
callback(err, null);
} else{
callback(null, data);
}
})
}
코드 작성이 완료되었으면 Lambda를 트리거할 API Gateway를 구축해보자 '
REST API 구축

리소스 생성
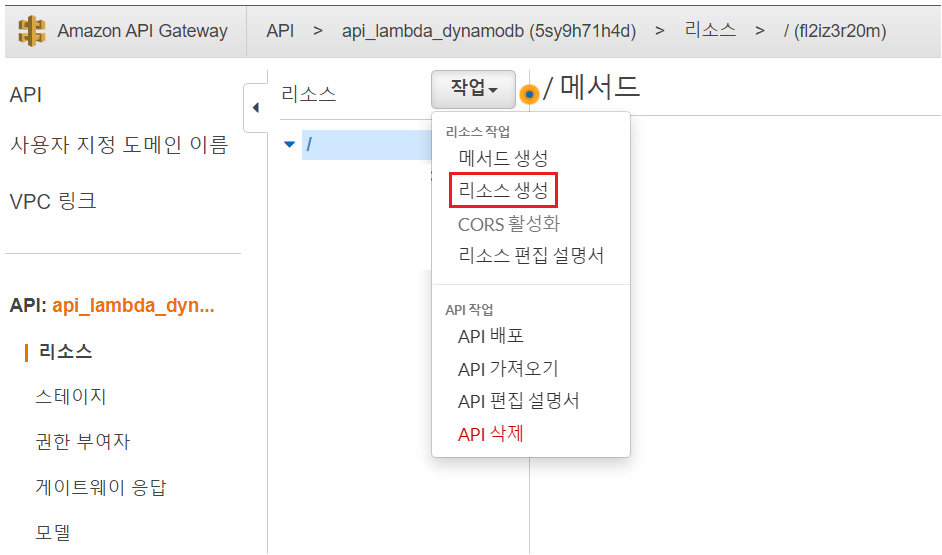

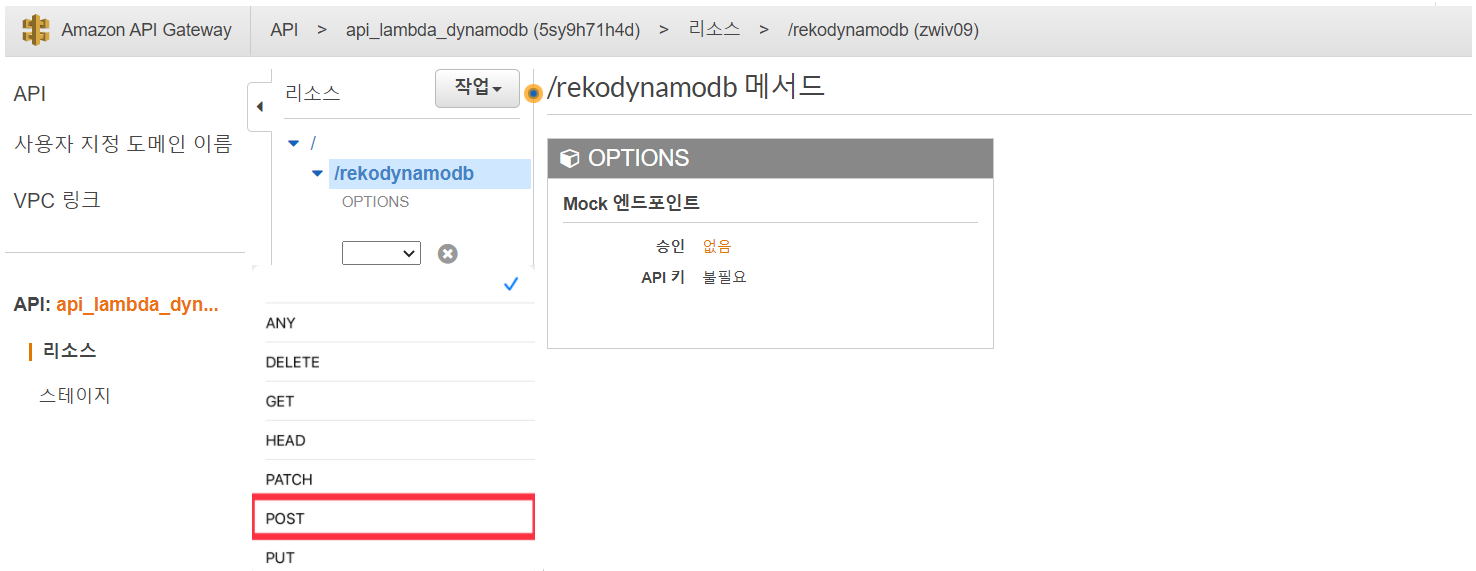
메서드 생성
마스크 착용 여부 데이터를 POST 방식으로 전달할 것이기 때문에 POST를 선택한다

통합 요청 설정
1. Lambda 함수 지정
POST 메서드를 실행하면 트리거할 Lambda 함수를 선택한다(앞서 만든 Lambda 함수 선택)


2. 매핑 템플릿 설정(application/json)
POST로 전달받은 값이 매핑템플릿에 정의된 형식으로 넘겨질 때만 허용한다
템플릿을 작성한 후 아래의 저장 클릭



CORS 활성화
CORS 활성화를 시켜주면 브라우저에서 비 단순 HTTP 요청을 받을 경우 CORS 프로토콜은 브라우저에 preflight 요청을 서버로 보내고, 서버 승인(또는 자격 증명에 대한 요청)을 기다린 후 실제 요청을 보내도록 요구한다


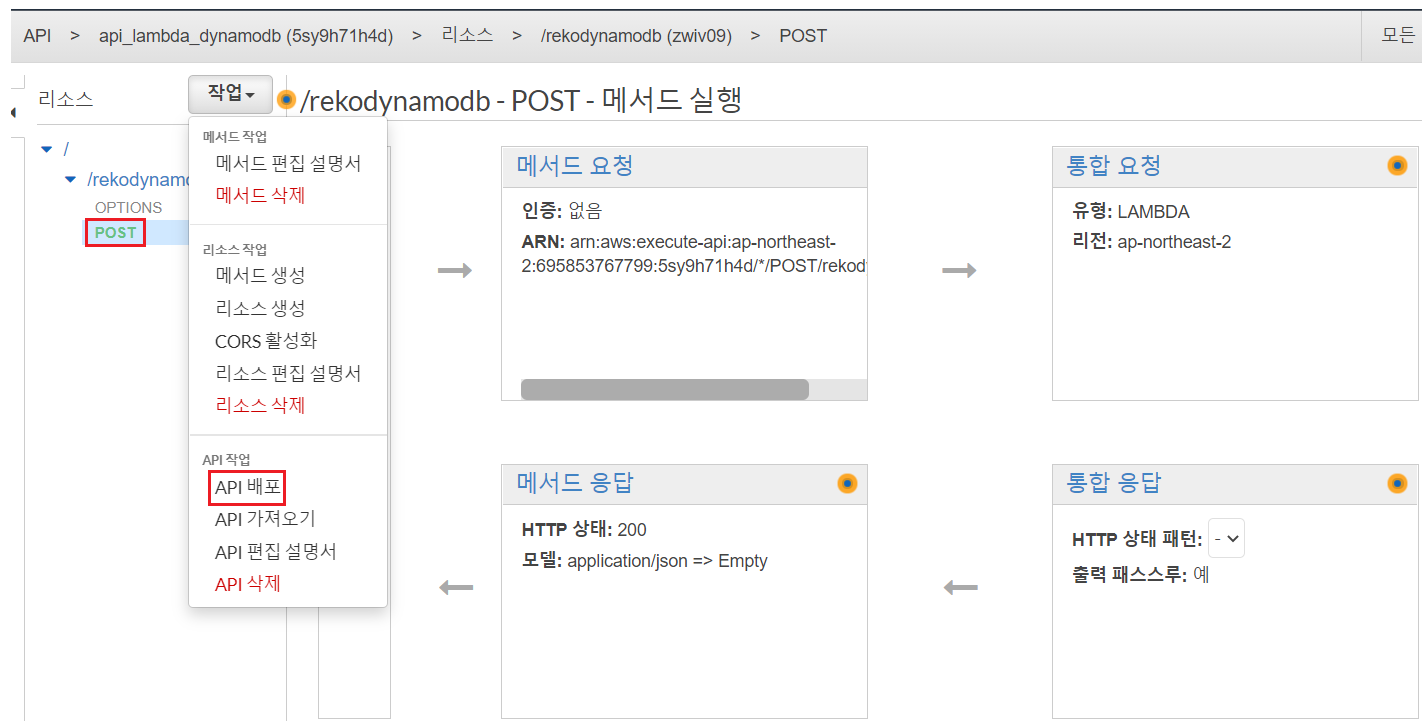
API 배포
지금까지 설정해준 API 를 배포시킨다(POST를 먼저 클릭한 다음 작업 메뉴의 API 배포를 선택한다)
API를 배포할 스테이지 지정하는 것으로 현재 개발 단계이므로 "backdev"라고 한다

배포 확인

트리거 설정
생성한 API Gateway를 Lambda 함수 트리거로 추가한다


이제 "API 엔드포인트"로 JSON 형식의 데이터를 전달하면 Lambda가 호출되어 전달받은 데이터를 DynamoDB에 저장하게된다

테스트
API Gateway - Lambda - DynamoDB 연결이 잘 되었는지 API Gateway 콘솔에서 테스트한다
요청본문에 다음과 같이 JSON 형식의 데이터를 입력하고 테스트를 클릭한다
{
"user_id": 10000,
"device_id": "A001",
"PN": "P",
"temperature": 36.5,
"mask": "정상착용",
"check_day": 210414,
"check_time": "12:30",
"location": "서울시 마포구"
}
리소스 간의 연결에 문제가 없고 데이터가 잘 전달되었다면 요청을 성공했음을 나타내는 상태 코드(200)를 출력하면서
동시에 DynamoDB에 데이터들이 저장된 것을 확인할 수 있다


이제부터는 QuickSight에서 DynamoDB 데이터를 시각화할 수 있도록 Athena 데이터 커넥터를 사용하여여 DynamoDB 데이터를 쿼리할 것이다
Athena 사용하기
1. Athena 쿼리 결과 데이터를 저장할 S3 버킷 생성
Athena 쿼리 결과 및 데이터 커넥터 유출 데이터를 저장하는 데 사용할 수 있는 버킷을 생성한다
Athena로 데이터 쿼리 시 쿼리 결과가 csv 파일로 생성되기 때문에 파일을 저장할 S3 버킷과 쿼리 도중 유출되는 데이터를 저장할 버킷 2개를 미리 생성해야 한다
버킷 안에 데이터를 저장할 폴더를 생성한다(Athena 설정 시 필요)
-쿼리 결과 버킷-

-유출 데이터 버킷-

2. 작업그룹 생성

작업그룹이름과 쿼리 결과 위치를 입력한다
쿼리 결과 위치에는 쿼리 결과 버킷의 경로를 입력한다(맨마지막에 / 붙이기)

Athena engin version1은 곧 사용이 중단되므로 version2를 선택한다

primary가 기본 작업 그룹으로 설정되어 있을 것이다. 방금 생성한 작업그룹을 선택한 다음 '작업 그룹 전환' 메뉴를 클릭하여 작업그룹을 활성화시킨다

3. 데이터 원본 연결(데이터 커넥터 생성)
Athena Engine 버전 2 작업 그룹이 생성되면 DynamoDB Athena 데이터 커넥터를 생성해보자


'새 AWS Lambda 함수 구성'을 클릭하여 사전 구축 된 AthenaDynamoDBConnector 애플리케이션을 배포한다
AthenaDynamoDBConnector 애플리케이션이란 Athena와 DynamoDB를 연결해주는 커넥터이다
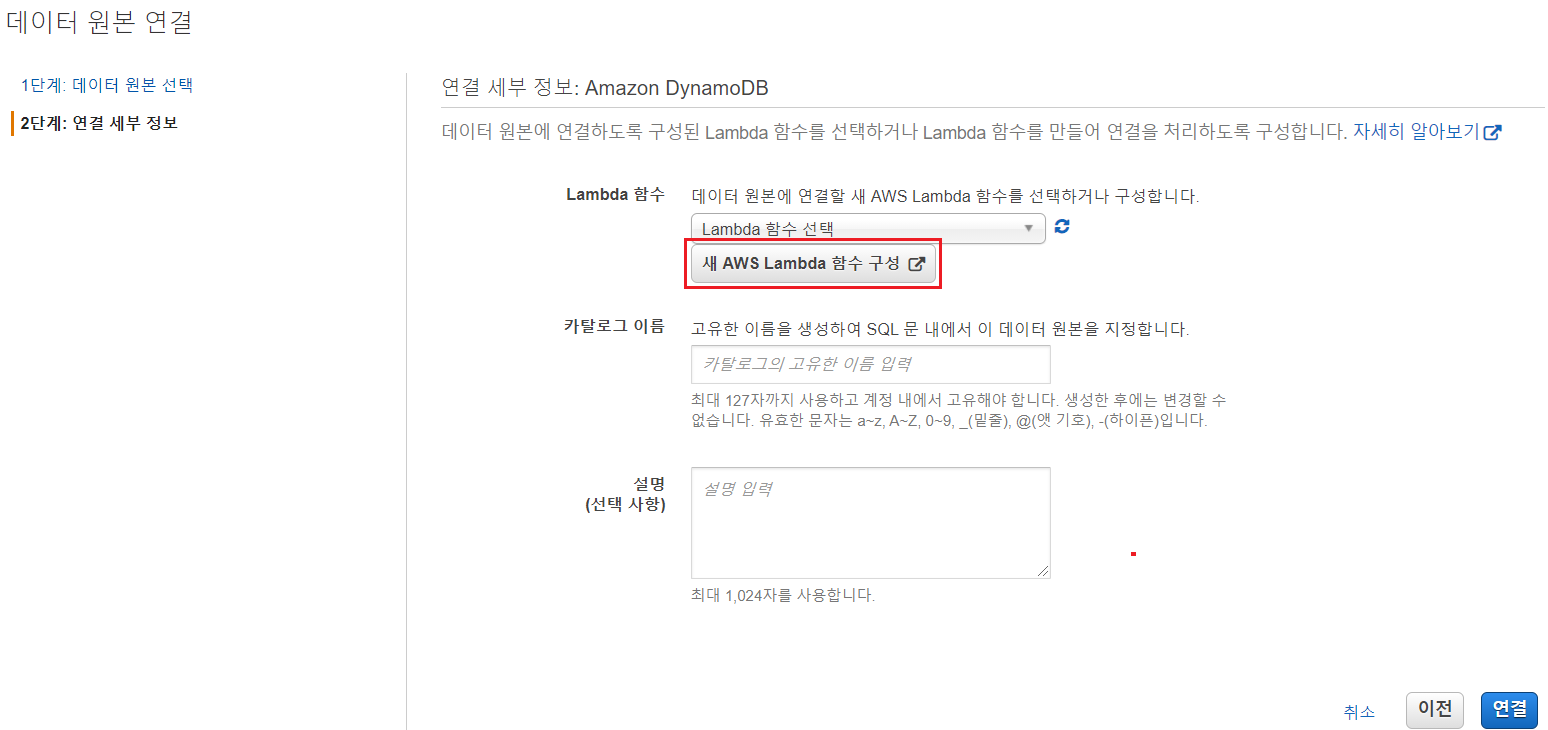
애플리케이션 설정 새 창이 열리면 SpillBucket및 SpillPrefix, AthenaCatalogName 매개 변수에 값을 입력한다
배포를 클릭하고 잠시 후 함수가 생성되는 것을 확인할 수 있다
생성된 함수에 대한 설명을 보면 Athena와 DynamoDB 간의 통신을 가능하게 해주고, SQL을 통해 테이블에 접근할 수 있도록 한다는 내용으로 즉, Athena와 DynamoDB를 연결해주는 커넥터 역할을 한다는 것이다


모든 설정이 완료되면 Athena를 사용하여 리소스에 제공 한 데이터 원본 및 카탈로그 이름을 사용하여 DynamoDB 데이터를 쿼리 할 수 있어야한다


쿼리 결과는 S3 쿼리 결과 버킷에 csv 파일로 저장되는 것을 확인할 수 있다

QuickSight - Athena 연동하기
Athena 데이터 커넥터는 Lambda를 호출하여 DynamoDB 데이터를 쿼리하고 반환하는 방식으로 작동한다. 따라서 QuickSight에서 Lambda 함수를 호출하려면 QuickSight의 서비스 역할 권한(Lambda 호출 권한)을 부여해야한다
Quicksight 사용자, 계정, 보안 등의 설정을 하기 위해선 버지니아 북부로 이동해야 한다
1. QuickSight 역할 설정
QuickSight로 이동하여 보안 및 권한 메뉴에서 'IAM 정책 할당'을 클릭한다


할당 이름은 "aws-quicksight-service-role-" 형식으로 생성한다

실습이므로 Lambda_FullAccess 정책을 선택한다

할당한 정책을 활성화 한다

<정책을 할당하지 않은 경우 발생하는 에러>

2. S3버킷 정책 추가
QuickSight가 Athena 쿼리 결과 버킷에 접근할 수 있도록 버킷 정책을 설정한다
QuickSight가 DynamoDB를 시각화할 때 Athena가 DynamoDB를 쿼리한 결과(S3에 저장된 csv 파일)를 가져와서 사용하기 때문에 쿼리 결과가 저장된 버킷에 접근할 수 있어야 한다

<버킷 정책을 추가하지 않은 경우 발생하는 에러>

3. Athena 작업 그룹 접근 권한 부여
QuickSight에서 Athena에 접근하기 위해서는 Workgroup 검색이 가능해야하므로 AWSQuicksightAthenaAccess정책을 부여해야한다. 정책 할당 방법은 1번과 같다

<정책을 할당하지 않은 경우 발생하는 에러>

권한 설정까지 모두 완료되었으면 QuickSight에서 DynamoDB를 시각화해보자
QuickSight에 Athena 데이터 세트 추가
QuickSight 좌측 메뉴에서 '데이터 세트'를 선택한다

'새 데이터 세트' 클릭

Athena 선택(데이트 세트 생성 메뉴에는 DynamoDB가 없기 때문에 Athena를 이용함)

데이터 원본 이름(임의로 설정)과 Athena Workgroup을 입력하고 데이터 원본 생성을 클릭한다

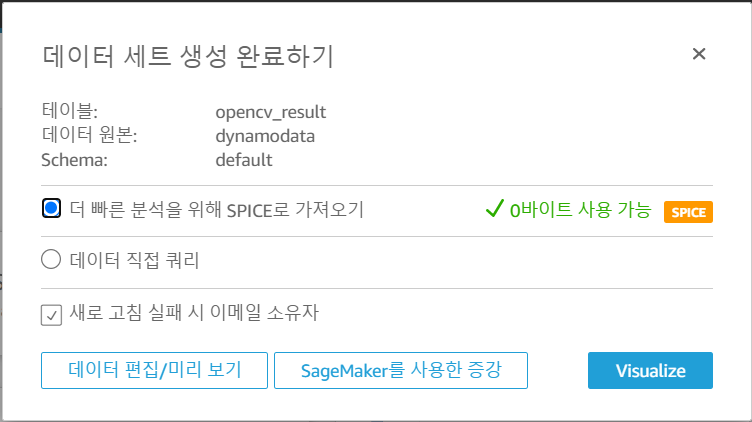
시각화하려는 DynamoDB 테이블을 선택한다

데이터 직접 쿼리보다 SPICE로 가져오는게 쿼리 속도가 더 빠르다
2가지 타입 중 하나를 선택한 다음 Visualize 클릭한다
다시 데이터 세트로 오면 방금 추가한 DynamoDB 테이블이 데이터 세트에 추가된 것을 확인할 수 있다

데이터 세트를 클릭하면 다음과 같은 화면이 뜨고 '분석 생성'을 클릭하면 opencv_result 데이터 세트에 대한 분석이 대시보드에 생성된 것을 볼 수 있다


분석을 클릭하고 들어가면 QuickSight의 여러 기능들을 통해 DynamoDB 데이터를 시각화할 수 있다
