Cloud Spanner
Spanner란?
-
NewSQL 데이터베이스
-
NoSQL 데이터베이스의 확장성을 가진 관계형 데이터베이스
특징
-
관계형 데이터베이스와 같이 스키마에 정의된 유형과 일치하지 않는 데이터를 추가하면 오류가 발생한다
-
Cloud Spanner 인스턴스는 여러 개의 데이터베이스를 내포하고 있는 컨테이너 역할을 한다
-
내포하고 있는 여러 개의 데이터베이스는 각각 다른 영역에 생성되는데 이는 데이터가 복제되는 영역을 결정한다
-
Spanner 인스턴스 안에 있는 각각의 데이터베이스는 특정 수의 노드를 가지고 있는데 노드를 통해 인스턴스의 데이터를 제공한다
-
Spanner 인스턴스는 자동으로 복제되고 이 때 노드도 함께 복제된다
인스턴스 복제
-
Cloud Spanner 인스턴스를 생성할 때 특정 위치에서 리전 인스턴스를 선택하거나 다중 리전 인스턴스를 선택할 수 있다
-
지역은 최대 4개까지 선택 가능하고 한 지역 내의 3개 영역에 분산 및 복제를 할 수 있다
-
영역 내에는 여러 개의 데이터베이스가 있다

인터리브 테이블
서버를 운영하면서 보관해야할 데이터 양이 많아지거나 데이터 처리량이 급증할 경우 데이터베이스는 읽기 복제본을 생성하여 부하를 줄일 수 있다. 하지만 읽기뿐만 아니라 수정사항도 많아진다면 이는 결국 하나의 데이터베이스가 모두 처리해야한다는 의미이기도 하다. 이러한 문제에 대한 솔루션으로 인터리브 테이블을 사용할 수 있다.
인터리브 테이블은 한 테이블이 다른 테이블과 연관되는 것으로 하나의 테이블에 들어있는 데이터를 여러 개의 데이터베이스에 분할한다. 예를 들어 어떤 학교의 학생 테이블이 있을 때 학생들 모두를 한 데이터베이스에 저장하는 것이 아니라 학과를 기준으로 나누어 여러 개의 데이터베이스에 저장하는 것이다. 이렇게 하면 처리량을 증가시킬 수 있다.
위의 설명에서는 단일 테이블 때를 얘기했지만, 만약 두 테이블을 JOIN할 계획이라면 모든 데이터를 일관되게 분할해야 한다. 예를 들어 직원 이름과 월급을 합산하기를 원하는데 직원 테이블은 A장비에, 급여 정보 테이블은 B장비에 나누어져 있으면 쿼리를 사용하기가 매우 어려워진다. 따라서 직원 테이블을 상위 테이블로, 급여 정보는 자식 테이블로 인터리브하여 직원과 급여가 서로 가까이에 있게 만든다.
예시)
학생ID와 과목 성적을 저장하는 테이블을 ID별로 분할하면 학생의 성적은 A장비에 저장되고, 학생정보는 B장비에 각각 저장되게 되어 JOIN과 같은 쿼리를 실행하기에 어려워진다. 따라서 인터리브 테이블을 사용하여 학생 데이터를 부모 테이블, 과목 성적 테이블은 자식 테이블로 인터리브하여 서로 가까이에 있게 한다.
| 학생(Student) | 과목 성적(Subject) | ||||
| Student_ID | Name | Subject_ID | Student_ID | Score | Grade |
| 1 | Tom | 1 | 3 | 80 | B |
| 2 | Bob | 2 | 2 | 90 | A |
Subject(2,2)에서 괄호 안에 들어있는 숫자의 의미는 앞에 있는 숫자는 부모 테이블인 Student 테이블의 Student_ID를, 뒤에 있는 숫자는 부모 테이블의 자식테이블인 자신의 Subject_ID를 의미한다.
| ID | Name | Score | Grade |
| Student(1) | Tom | ||
| Student(2) | Bob | ||
| Subject(2,2) | 90 | A | |
| Student(3) | Jun | ||
| Subject(3,1) | 80 | B |
밑에 보이는 것처럼 학생 테이블과 과목 성적 테이블이 분리되어 있지 않아도 관련 데이터가 함께 있는 것을 볼 수 있다.

이제 Cloud Spanner 인스턴스에 데이터를 삽입하고 조회 방법을 알아보자
Spanner 사용을 위한 기본 설치
Spanner는 다른 관계형 데이터베이스와 다르게 INSERT SQL명령, UPDATE SQL 명령을 지원하지 않는다
쿼리 인터페이스 대신 별도의 API를 사용하여 Cloud Spanner에 작성한다
@google-cloud/spanner 패키지를 설치한다
$ npm install @google-cloud/spanner@0.7.0
Cloud Spanner에 nodejs로 스크립트를 작성하기 때문에 nodejs를 설치한다
$ sudo apt install nodejs
설치된 node의 버전 확인
$ node --version
npm을 사용하는 프로젝트에서 의존성을 추가하거나 npm audit 명령어를 사용했을 때 그 dependency tree의 보안 취약점과 해결 방안을 제공해준다. 이 제공된 정보를 통해 Node를 사용하는 오픈소스 프로젝트와 애플리케이션 모두 견고하고 완전하게 만들 수 있다
*npm은 자바스크립트 프로그래밍 언어를 위한 패키지 관리자이자 자바스크립트 런타임 환경 Node.js의 기본 패키지 관리자이다.
$ npm audit
npm audit fix 는 npm audit 을 통해 나온 보안 취약점 결과들을 자동적으로 고쳐준다
$ npm audit fix
vi 편집기를 설치한다
$ sudo apt install vim
Cloud Spanner 인스턴스/데이터베이스/테이블 생성

Cloud Spanner 인스턴스가 생성되었으면 데이터베이스 만들기를 클릭한다


데이터베이스를 생성하고 테이블 만들기를 클릭해서 employees 테이블을 만든다


테이블까지 만들어졌으면 Spanner의 employees 테이블에 데이터를 추가하는 스크립트 작성을 해보자
데이터 삽입
Cloud Shell 활성화를 클릭하여 쉘 스크립트 창을 연 다음 insert.js 라는 파일을 생성하고 데이터를 추가하는 스크립트를 작성한다(밑줄 그은 부분은 차례대로 자신의 프로젝트ID, Spanner 인스턴스ID, 데이터베이스ID, 테이블명을 적는다)

스크립트 실행
$ node insert.js
"Saved data!"가 출력된다면 데이터가 정상적으로 추가된 것이다

콘솔창에서 확인해보면 데이터가 추가된 것을 확인할 수 있다

데이터 쿼리방법
*데이터 삽입과 마찬가지로 파일을 만들고 쿼리를 수행할 스크립트를 작성한 뒤 스크립트를 실행시킨다
1) Spanner의 읽기 API를 사용하여 단일 테이블을 쿼리할 수 있다
특정 키 조회를 통해 행을 검색할 수 있다
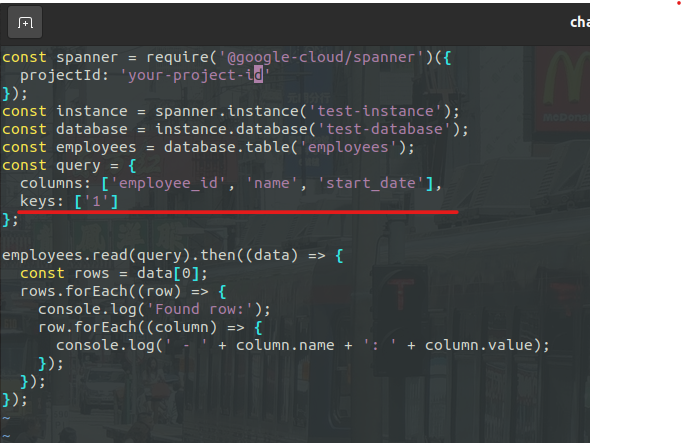

2) 일반적인 SQL쿼리 API를 사용하여 다른 테이블을 포함할 수 있다
WHERE절을 사용하여 id가 2인 사람을 조회하기 위해 매개변수를 대체 사용한다(밑줄 그은 부분)

ID가 2번인 'Bill Gate'의 정보가 조회되었다

색인
색인은 임의의 특정 열을 정렬하여 저장하는 것으로 데이터 쿼리를 실행할 때 색인을 참조하여 더 빠르게 수행하도록 해준다. 예를 들어 우리 회사 직원 정보가 담겨져 있는 책(무작위로 적혀있음)에서 이름이 "Tom"이라는 사람을 찾을려고 한다면 시간이 직원이 많을수록 오래 걸릴 것이다. 하지만 이름 알파벳을 기준으로 정렬되어 있는 책에서 찾는다면 훨씬 빨리 찾을 수 있을 것이다.
색인을 생성하고 색인을 사용한 쿼리를 실습해보자
직원 이름 속성에 색인을 생성한다


직원의 이름으로 조회 및 검색을 실행해보니 전체 테이블을 스캔하는 대신 새로 생성된 "employees_by_name" 색인을 스캔한 것을 볼 수 있다.

이처럼 자주 사용하는 열들을 색인에 저장해놓고 쿼리를 수행하면 전체 테이블을 스캔하는 것보다 더 빨리 결과를 얻을 수 있다.
[참조사이트] medium.com/google-cloud/first-steps-with-google-cloud-spanner-e9a135ded285
First Steps with Google Cloud Spanner
Setting up and managing a distributed database for better scalability and high availability is difficult and can cause numerous operational…
medium.com